!nvcc --version2 Getting started with CUDA
![]()
In this notebook, we dive into basic CUDA programming in C. If you don’t know C well, don’t worry, the code is straightforward with a focus on the CUDA considerations. Doing the exercises and following the examples can help with low-level understanding, which can often be abstracted away by the equivalent Python libraries.
2.1 Parallel programming
GPU programming fundamentally transforms how we approach computational tasks by leveraging massive parallelization. The parallel model contrasts with traditional CPU processing, where tasks are done sequentially.
While sequential programming executes instructions one after another - like a single assembly line worker completing tasks in order - GPU parallel programming distributes work across thousands of smaller processing units simultaneously, similar to having thousands of workers each handling a small piece of the overall task.
The key to effective GPU programming lies in identifying problems that can be naturally parallelized and structuring algorithms to minimize sequential dependencies.

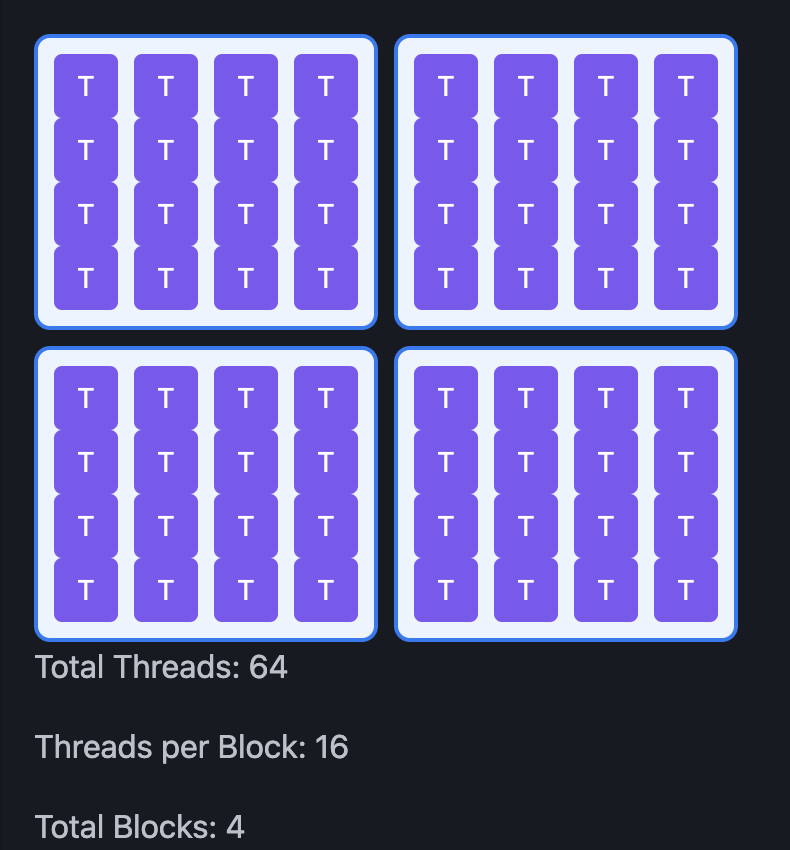
2.2 Threads and blocks
Let’s start to build an intuitive understanding of threads and blocks by looking at the visualizations at this interactive website.
2.3 Resources
We can do all exercises on the free T4 GPU on Colab.
Let’s check we have the Nvidia CUDA Compiler Driver (NVCC) installed:
!pip install nvcc4jupyter%load_ext nvcc4jupyter2.4 Writing and running C code in a Colab
Thanks to the nvcc4jupyter extension, we can run C/C++ code from our notebook cells.
Simply annotate each code cell with %%cuda at the top.
Syntax checking may mean a lot of read and yellow lines on our code, since it’s focused on Python code, so it’s best to turn this feature off: Settings -> Editor -> Code diagnostics -> None.
2.5 Hello, World!
%%cuda
#include <stdio.h>
void hello()
{
printf("Hello from the CPU.\n");
}
int main()
{
hello();
return 0;
}2.6 and from the GPU
Let’s adjust the code to make it run on the GPU.
We will need to annotate functions with
__global__
and synchronize our code on the completion of the kernel using the method
cudaDeviceSynchronize();
%%cuda
#include <stdio.h>
__global__ void helloGPU()
{
printf("Hello from the GPU.\n");
}
int main()
{
helloGPU<<<1, 1>>>();
cudaDeviceSynchronize();
}2.7 Blocks and threads
You may be wondering why we have triple angle brackets in the function call:
<<<1, 1>>>
These are required parameters for CUDA denoting the blocks and threads in which our tasks should run.
<<< NUMBER_OF_BLOCKS, NUMBER_OF_THREADS_PER_BLOCK>>>
Threads and blocks are fundamental for organizing parallel computation on GPUs. Threads are the smallest unit of action, each capable of running a single instance of the kernel function.
Threads are grouped into blocks, where they can cooperate and share resources.
Multiple blocks form a grid, the highest level of CUDA hierarchy.
kernelA <<<1, 1>>>() runs one block with a single thread so will run only once.
kernelB <<<1, 10>>>() runs one block with 10 threads and will run 10 times.
kernelC <<<10, 1>>>() runs 10 thread blocks, each with a single thread so will run 10 times.
kernelD <<<10, 10>>>() runs 10 blocks which each have 10 thread, so run 100 times.
The next example illustrates the use of threads for parallel action. Experiment with changing the <<<blocks, threads>>> and see the results.
%%cuda
#include <stdio.h>
__global__ void printInts()
{
for(int i=0; i<10; i++)
{
printf("%d ", i);
}
}
int main()
{
printInts<<<1, 1>>>();
cudaDeviceSynchronize();
}2.8 Threads and indexes
Each thread has an index denoting its place in a block. Blocks also are indexed, and grouped into a grid.
There are useful methods for identifying these indexes:
threadIdx.x : identifies the index of the thread blockIdx.x : identifies the index of the block blockDim.x : represents the number of threads in a block
For example, here is a classical loop:
%%cuda
#include <stdio.h>
void loop(int n)
{
for(int i=0; i<n; i++)
{
printf("This is loop cycle %d ", i);
}
}
int main()
{
loop(10);
}We can accelerate this operation by launching the iterations in parallel, a multi-block loop. Let’s use two blocks of threads.
Here, blockIdx.x * blockDim.x + threadIdx.x gives threads unique indexes in a grid.
%%cuda
#include <stdio.h>
__global__ void loop()
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
printf("This is loop cycle %d\n", i);
}
int main()
{
loop<<<2, 5>>>();
cudaDeviceSynchronize();
}2.9 Allocating memory
CUDA version 6 and above has simplified memory allocation for both the CPU host and as or or many GPU devices with little additional work necessary by the developer.
C uses calls to malloc and free to allocate and liberate memory; we simply replace these with cudaMallocManaged and cudaFree.
%%cuda
#include <stdio.h>
#include <stdlib.h>
// CPU-only
int square(int x)
{
return x = x * x;
}
int main()
{
int N = 100000;
size_t size = N * sizeof(int);
int *a = (int *)malloc(size);
// Fill array with numbers 1-20
for (int i = 0; i < N; i++) {
a[i] = i + 1;
}
// Square each number and print
printf("Original -> Squared\n");
for (int i = 0; i < N; i++) {
int result = square(a[i]);
printf("%2d -> %4d\n", a[i], result);
}
free(a);
return 0;
}2.10 Profiling
Let’s create an executable with the same code so we can profile and time it. To do that, we write a file using cell magic functions, compile and run.
%%writefile square.c
#include <stdio.h>
#include <stdlib.h>
// CPU-only
int square(int x)
{
return x = x * x;
}
int main()
{
int N = 100000;
size_t size = N * sizeof(int);
int *a = (int *)malloc(size);
// Fill array with numbers 1-20
for (int i = 0; i < N; i++) {
a[i] = i + 1;
}
// Square each number and print
printf("Original -> Squared\n");
for (int i = 0; i < N; i++) {
int result = square(a[i]);
printf("%2d -> %4d\n", a[i], result);
}
free(a);
return 0;
}!gcc square.c -o square2.11 Time it
!time ./square2.12 Exercise: CUDA version
Let’s use cudaMallocManaged and cudaFree. Developers often prefix variables to be put on the device with d_, we will write device_ to make this clear.
%%cuda
#include <stdio.h>
#include <stdlib.h>
// Accelerated
int N = 100000;
size_t size = N * sizeof(int);
int *device_a;
/*
Here is our earlier square function:
int square(int x)
{
return x = x * x;
}
*/
// Initialize the array
void init(int *a, int N)
{
int i;
for (i = 0; i < N; ++i)
{
a[i] = i;
}
}
/*
Here is our earlier square function:
int square(int x)
{
return x = x * x;
}
How can we make this into a CUDA function?
Remember the threadIdx.x etc methods to
create a unique index for each thread across all blocks
*/
__global__ void square_kernel(int *device_a, int n)
{
// initialize an index variable
// Your code here;
if (idx < n) {
// square the device array at the index
// Your code here
}
}
// Use `a` on the CPU and/or on any GPU in the accelerated system.
int main() {
// Use cudaMallocManaged to allocate memory for the device array
// and the size variable
// Your code here
// Initialize the array
for (int i = 0; i < N; i++) {
device_a[i] = i + 1; // Values will be 1, 2, 3, ..., 10
}
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
square_kernel<<<blocksPerGrid, threadsPerBlock>>>(device_a, N);
cudaDeviceSynchronize();
printf("Squared array:\n");
for (int i = 0; i < N; i++) {
printf("%d ", device_a[i]);
}
cudaFree(device_a);
return 0;
}
2.13 Solution
%%cuda
#include <stdio.h>
#include <stdlib.h>
// Accelerated
int N = 100000;
size_t size = N * sizeof(int);
int *device_a;
__global__ void square_kernel(int *device_a, int n)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < n) {
device_a[idx] = device_a[idx] * device_a[idx];
}
}
// Use `a` on the CPU and/or on any GPU in the accelerated system.
int main() {
// Note the address of `a` is passed as first argument.
cudaMallocManaged(&device_a, size);
// Initialize the array
for (int i = 0; i < N; i++) {
device_a[i] = i + 1; // Values will be 1, 2, 3, ..., 10
}
int threadsPerBlock = 8;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
square_kernel<<<blocksPerGrid, threadsPerBlock>>>(device_a, N);
cudaDeviceSynchronize();
printf("Squared array:\n");
for (int i = 0; i < N; i++) {
printf("%d ", device_a[i]);
}
cudaFree(device_a);
return 0;
}
Let’s take the same approach to time our CUDA equivalent square function.
%%writefile square.cu
#include <stdio.h>
#include <stdlib.h>
// Accelerated
int N = 100000;
size_t size = N * sizeof(int);
int *device_a;
__global__ void square_kernel(int *device_a, int n)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < n) {
device_a[idx] = device_a[idx] * device_a[idx];
}
}
// Use `a` on the CPU and/or on any GPU in the accelerated system.
int main() {
// Note the address of `a` is passed as first argument.
cudaMallocManaged(&device_a, size);
// Initialize the array
for (int i = 0; i < N; i++) {
device_a[i] = i + 1; // Values will be 1, 2, 3, ..., 10
}
int threadsPerBlock = 8;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
square_kernel<<<blocksPerGrid, threadsPerBlock>>>(device_a, N);
cudaDeviceSynchronize();
printf("Squared array:\n");
for (int i = 0; i < N; i++) {
printf("%d ", device_a[i]);
}
cudaFree(device_a);
return 0;
}!nvcc -o cuda_square square.cu!nvprof ./cuda_square!time ./cuda_square2.14 Grid stride
Let’s remind ourselves: grids are the highest level of the GPU hierarchy:
Threads -> Blocks -> Grids
Often in CUDA programming, the number of threads in a grid is smaller than the data upon which we operate.
If we have an array of 100 elements to do something with, and a grid of 25 threads, each grid will have to perform computation 4 times.
A thread at index 20 in the grid would:
- Perform its operation (eg squaring the element) on element 20 of the array
- Increment its index by 25, the size of the grid, to 45
- Perform its operation on element 45 of the array
- Increment its index by 25, to 70
- Perform its operation on element 70 of the array
- Increment its index by 25, to 95
- Perform its operation on element 95 of the array
- Stop its work, since 120 is out of range for the array
We can use the CUDA variable gridDim.x to calculate the number of blocks in the grid. Then we calculate the number of threads in each block, using
gridDim.x * blockDim.xHere is a grid stride loop in a kernel:
__global__ void kernel(int *a, int N)
{
int indexInGrid = threadIdx.x + blockIdx.x * blockDim.x;
int gridStride = gridDim.x * blockDim.x;
for (int i = indexInGrid; i < N; i += gridStride)
{
// do something to a[i];
}
}2.15 Exercise
For this exercise, we use the %%writefile magic function to create a file so we can then generate an outputs for a visualization, rather than running it inline with %%cuda.
%%writefile grid_stride.cu
#include <stdio.h>
void init(int *a, int N)
{
int i;
for (i = 0; i < N; ++i)
{
a[i] = i;
}
}
__global__
void squareElements(int *a, int N)
{
/*
* Use a grid-stride loop to ensure each thread works
* on more than one array element
*/
int idx = // Your code here
int stride = // Your code here
for (int i = idx; i < N; i += stride)
{
int old_value = a[i];
a[i] *= i;
printf("Thread %d (Block %d, Thread in Block %d) processing element %d. Old value: %d, New value: %d\n",
idx, blockIdx.x, threadIdx.x, i, old_value, a[i]);
}
}
bool checkElementsSquared(int *a, int N)
{
int i;
for (i = 0; i < N; ++i)
{
if (a[i] != i*i) return false;
}
return true;
}
int main()
{
int N = 500;
int *a;
size_t size = N * sizeof(int);
// Use cudaMallocManaged to allocate memory for the array
// and the size variable
// Your code her
init(a, N);
// The size of this grid is 356 (32 x 8)
size_t threads_per_block = 32;
size_t number_of_blocks = 8;
squareElements<<<number_of_blocks, threads_per_block>>>(a, N);
cudaDeviceSynchronize();
bool areSquared = checkElementsSquared(a, N);
printf("All elements were doubled? %s\n", areSquared ? "TRUE" : "FALSE");
cudaFree(a);
}2.16 Solution
%%writefile grid_stride.cu
#include <stdio.h>
void init(int *a, int N)
{
int i;
for (i = 0; i < N; ++i)
{
a[i] = i;
}
}
__global__
void squareElements(int *a, int N)
{
/*
* Use a grid-stride loop to ensure each thread works
* on more than one array element
*/
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int stride = gridDim.x * blockDim.x;
for (int i = idx; i < N; i += stride)
{
int old_value = a[i];
a[i] *= i;
printf("Thread %d (Block %d, Thread in Block %d) processing element %d. Old value: %d, New value: %d\n",
idx, blockIdx.x, threadIdx.x, i, old_value, a[i]);
}
}
bool checkElementsSquared(int *a, int N)
{
int i;
for (i = 0; i < N; ++i)
{
if (a[i] != i*i) return false;
}
return true;
}
int main()
{
int N = 500;
int *a;
size_t size = N * sizeof(int);
cudaMallocManaged(&a, size);
init(a, N);
// The size of this grid is 356 (32 x 8)
size_t threads_per_block = 32;
size_t number_of_blocks = 8;
squareElements<<<number_of_blocks, threads_per_block>>>(a, N);
cudaDeviceSynchronize();
bool areSquared = checkElementsSquared(a, N);
printf("All elements were doubled? %s\n", areSquared ? "TRUE" : "FALSE");
cudaFree(a);
}!nvcc -o grid_stride grid_stride.cu
!./grid_stride > output.txt2.17 Visualizing the grid stride
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import re
from google.colab import files
%matplotlib inline
def parse_line(line):
pattern = r"Thread (\d+) \(Block (\d+), Thread in Block (\d+)\) processing element (\d+)\. Old value: (\d+), New value: (\d+)"
match = re.search(pattern, line)
if match:
return {
'Thread ID': int(match.group(1)),
'Block ID': int(match.group(2)),
'Thread in Block': int(match.group(3)),
'Element Index': int(match.group(4)),
'Old Value': int(match.group(5)),
'New Value': int(match.group(6))
}
return None
# Read the output file and parse it into a DataFrame
data = []
print("Reading file...")
with open('output.txt', 'r') as f:
content = f.read()
print(f"File content (first 500 characters):\n{content[:500]}")
# Use regex to find all matches in the entire content
pattern = r"Thread (\d+) \(Block (\d+), Thread in Block (\d+)\) processing element (\d+)\. Old value: (\d+), New value: (\d+)"
matches = re.finditer(pattern, content)
for i, match in enumerate(matches, 1):
data.append({
'Thread ID': int(match.group(1)),
'Block ID': int(match.group(2)),
'Thread in Block': int(match.group(3)),
'Element Index': int(match.group(4)),
'Old Value': int(match.group(5)),
'New Value': int(match.group(6))
})
if i % 100 == 0:
print(f"Processed {i} matches...")
print(f"Number of parsed data points: {len(data)}")
df = pd.DataFrame(data)
# Print DataFrame info for debugging
print("\nDataFrame Info:")
print(df.info())
print("\nFirst few rows of the DataFrame:")
print(df.head())
if df.empty:
print("The DataFrame is empty. No visualizations will be created.")
else:
# Create a scatter plot
plt.figure(figsize=(12, 8))
sns.scatterplot(data=df, x='Element Index', y='Thread ID', hue='Block ID', palette='viridis', s=50)
plt.title('Grid Stride Pattern Visualization')
plt.xlabel('Array Element Index')
plt.ylabel('Thread ID')
plt.legend(title='Block ID', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.tight_layout()
plt.show()
# Create a heatmap to show the distribution of work across threads and blocks
plt.figure(figsize=(12, 8))
heatmap_data = df.pivot_table(values='Element Index', index='Block ID', columns='Thread in Block', aggfunc='count')
sns.heatmap(heatmap_data, cmap='YlOrRd', annot=True, fmt='d', cbar_kws={'label': 'Number of Elements Processed'})
plt.title('Distribution of Work Across Threads and Blocks')
plt.xlabel('Thread in Block')
plt.ylabel('Block ID')
plt.tight_layout()
plt.show()
# Calculate and print the stride
stride = df.groupby('Thread ID')['Element Index'].diff().dropna().mode().iloc[0]
print(f"\nStride (most common difference between consecutive elements for a thread): {stride}")
print("Script execution completed.")